Clinical trials are short, but the benefits of many drugs lasts months or even years beyond the duration of these trials. To quantify the full costs and benefits of a treatment over time (for instance as used for HTA purposes), one must extrapolate this clinical benefits. Commonly, this extrapolation is done using a parametric function (as recommended by NICE’s Decision Support Unit (DSU) technical support document on survival analysis (TSD 14). One challenge is that the parametric functions used to extrapolate survival aren’t typically very flexible. As Latimer and Rutherford (2024) write of these limitations:
in particular, exponential, Weibull, Gompertz and Gamma models cannot cope with any turning points in the hazard function over time (that is, the rate at which the event of interest occurs over time), and log-logistic, log normal and Generalised Gamma models can only cope with one turning point
With new therapies (e.g., CAR T, immuno-oncology) offering long-term, durable survival gains, these standard parametric approaches may not sufficiently capture the likely survival profile. Even in the absence of fully curative treatment, there may be reasons why cure models are useful. Specifically,
Participants with the worst prognosis are likely to die first, changing the prognostic mix of those remaining in follow-up. This may result in a turning point in the hazard function, with the hazard of death reducing in the medium term. In the long term, hazards are likely to continue to fall and may even drop to levels expected in the general population— in which case, remaining patients may be considered to be cured.
Alternatively, payers may be hesitant to use a ‘cure’ model if there is limited data on (i) how long the cure will last and (ii) what share of individuals will be ‘cured’. However, an updated NICE technical support document (TSD 21) describes some of these more flexible methods.
The authors describe the cure models as partitioning all all-cause hazard h(t) into two components; the population hazard function h*(t) and the disease specific hazard λ(t). The population standard mortality ratios (SMRs) typically comes form age-sex life tables for the country of interest. One can estimate the overall survival risk of the disease R(t) as the ratio of all-cause survival S(t) and background population survival S*(t).
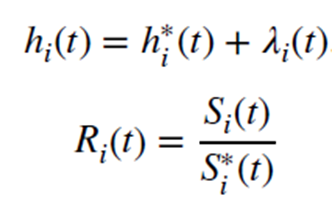
There are two types of cure models: mixture cure models (MCM) and non-mixture cure models (NMC). The authors explain MCM as follows:
MCMs assume that there are two groups of individuals – those who are cured of their disease and those who are not. When fitted in a relative survival framework, general population mortality rates are incorporated directly into the model and the model uses these, combined with the parametric distribution chosen to represent the uncured patients, to estimate the cure fraction. General population mortality rates are taken from relevant lifetables, with rates from the appropriate calendar year used, and these are further stratified by characteristics such as age and sex, so that each trial participant can be assigned an expected background mortality rate.
MCM mix cured and uncured populations where cured have general population mortality. However, it is important to note that modellers don’t “decide” the cure percentage; this is estimated from the data. Specifically, each individuals in the data set is not assigned to be cured or not; rather they are assigned a probability of being cured; one can only estimate the cure fraction at the population level by averaging these cure probabilities across the population.
To code up MCMs, one can use strsmix in Stata or flexsurv and cuRe in R.
NMC, in contrast, do split the population into cured and uncured groups directly. Rather, the ‘cure’ is defined as follows:
NMCs do not assume that there is a group of patients who are ‘cured’ at baseline. The timepoint at which cure occurs depends on when the modelled hazards converge with those observed in the general population. When fitted using standard parametric models, there is no constraint on when this convergence will occur.
Despite these different approaches, the authors note that the when MCM and NMC are fit with similar parametric distributions, the cure rates are often similar.
To code up NCMs, one could use strsnmix or stpm2 in Stata, or flexsurv, cuRe and rstpm2 in R.
I recommend you read the full paper. The remainder of the paper has empirical applications, tips on when one should (and should not) use cure models, and much more. A very interesting read.